Contents
- Overview
- Components
- Hardware and operating system
- Node setup
- Performance
- Maintenance
- Load-balancing inbound connections
Overview
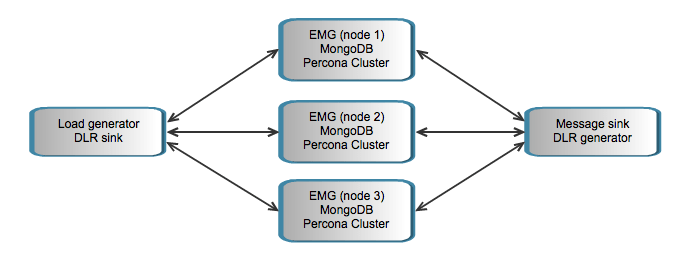
This is a sample setup of EMG 6 with 3 EMG active nodes for high availability. Database authentication and logging to MySQL (Percona) is enabled.
The nodes are fully redundant and any node can be taken offline at any point in time without downtime for the service as a whole. However, performance in a Percona XtraDB Cluster will be significantly better if you only write to one node at a time. Therefore setups where all nodes are written to at the same time should be avoided.
Please note that an uneven number of nodes are needed in the cluster and thus a minimum of three nodes is necessary. However, it is possible to set up a cluster with only two “data” nodes and the third node working as a “arbiter”. In this case only the two data nodes need to be dimensioned with sufficient CPU, RAM and disk storage to handle the data while the third node can be much simpler only participating in voting in the cluster.
As for disk space a rough estimation is that each message will uses 1 kB of disk space. So, 50 million messages would use around 50 GB of disk space. So, if you for example will process around 50 million messages per month and want to save 6 months of data (non-aggregated) it would correspond to 300 GB of disk.
Each message received by EMG is put in queue in MongoDB. It is then picked up from the queue and sent out. The sending part is likely to be performed by another EMG node than the node that received and queued it. Similarly the delivery report can be received by any node when it arrives, queued and then forwarded to a client connecting to any node.
Components
EMG 6.0 – EMG server (Linux 64-bit required for MongoDB support)
MongoDB 2.4.1 – Data store for internal EMG information such as message queues, open delivery reports etc
Percona XtraDB Cluster 5.5.29 – A drop-in replacement for MySQL enabling multi-master replication support
EMG 6.0
The EMG setup must be identical for the 3 nodes with two exceptions:
- A unique license key is required for each node
- The NODEID setting must be unique for each node
To simplify the configuration we use identical server.cfg files and the NODEID configuration is put in file server.cfg.<hostid> on each node.
The license information can go into license.<hostid>.
Thereby we can have the same configuration file set managed centrally and then “pushed out” to the 3 nodes.
MongoDB
MongoDB is a replication NoSQL database which can be used as the EMG data store.
The way MongoDB works is that it assigns one node as PRIMARY and the other nodes as SECONDARY. All writes are performed towards the primary node and replicated to the secondaries.
If the primary node goes down a new primary will automatically be selected among the secondaries as part of the failover process.
The number of nodes used must be odd.
Percona XtraDB Cluster
The Percona cluster stores EMG user information and the EMG message log (routelog). All records will be replicated between the nodes and thereby the full message log will be stored on all 3 nodes requiring quite a bit of space over time.
Each record in the database will need approx 0.5 kB (0.3 kB for routelog and 0.2 kB for messagelog). At a constant average speed of 100 mps this will generate around 4 GB of data per 24 hours.
If fulll logs should be kept for 3 months to be aggregated after that it would require approx 360 GB of disk space for the database.
Hardware and operating system
In this setup we have used fairly basic 1U rack-mounted servers (Dell Poweredge R320) running CentOS 6.4.
The servers have 2 SATA hard drives and 2 SSD hard drives paired up in RAID-1 volumes.
| Server | Dell Poweredge R320, 1U with H710 RAID controller |
| CPU | 1 x E5-2430, 2.20 GHz, 15M Cache (6 cores = 12 threads) |
| Memory | 32 GB, 1333 MHz RDIMMs |
| Disk | 2 x SATA HDD 500 GB, RAID-1 2 x SSD 160 GB, RAID-1 |
| OS | Centos 6.4, 64-bit |
The Intel 520 SSD disks are expected to have a minimum life time of 5 years with 20 GB of writes per day according to Intel specs and the RAID-1 config enables hot swap replacement.
Node setup
Each node has a minimal installation of CentOS 6.4 with EMG, MongoDB and Percona on top.
Percona (MySQL) is placed on HDD while EMG and MongoDB is placed on SSD. The main reason for this is that EMG and MongoDB will use a fairly fixed amount of space while the MySQL database will grow over time.
Also the database access can be handled by the SATA HDD drives boosted by the RAID controller cache while we want MongoDB (which is the bottleneck due to the replication) to be as fast as possible.
Performance
In total approx 450 messages per second in handled (and another 450 delivery reports per second).
Message load and sink
For load testing an additional separate server is used as a load generator and sink for messages and delivery reports.
It uses the “emgload” utility for sending messages to the EMG nodes via 10 SMPP connections all using a window size of 10.
The source and destination addresses are on the format “491234xxxxxxx”, in total 13 digits where the last 7 are random.
For each message a delivery report is requested.
Configuration
Various configuration parameters affect performance.
EMG log level
We use log level INFO in tests and when changing this to log level DEBUG we typically see a 10% performance decrease.
MongoDB write concern
The “write concern” option in MongoDB specifies when a transaction should be acknowledged to the client.
- 1 – Acknowledge when primary node has applied transaction
- 2 – Acknowledge when primary and one secondary node have applied transaction
In our test we use 1 as default.
Option 2 ensures that the transaction is not lost even if the primary node crashes since the transaction has been replicated to at least one more node. However, this extra security comes at a price since performance decreases with around 50%.
Network latency
The MongoDB replication process is expected to be the bottleneck in this setup. The network latency seen is typically around 0.100 ms (100 microsecs) when using “ping” between the hosts.
If latency can be decreased performance is likely to improve and the other way around.
Maintenance
Some information needs to be trimmed in order to avoid excess disk usage over time.
MongoDB
The number of records in the MongoDB databases will usually be fairly limited. The number of messages queued within EMG (optionally limited using EMG keyword MAXTOTALQUEUESIZE) and especially the number of open delivery reports (limited by EMG keyword DLRSSIZE) will be the key factors determining the number of records.
However, when records are deleted from MongoDB databases the space may not be reused and collections may grow over time. Therefore it may be necessary to “compact” the MongoDB collections on a regular basis. This can be done on a running server but the collection being compacted will be locked during the compact. For a small collection this takes less than one second but for a large collection it can take several minutes and should therefore be done during a maintenance window.
Sample MongoDB compact script (compact.js)
Percona
The routelog and messagebody tables will grow over time. It is recommended to trim these tables so that records older than 3 months, for example, are deleted. The data can of course be aggregated so that usage statistics is kept and can be displayed.
The script hourly_summary.pl, that is part of the EMG Portal distribution, is a Perl script that aggregates the number of messages sent together with price information per user per hour.
Load-balancing inbound connections
What is left out in this article is how inbound connections are distributed between the nodes but there are several such solutions available.
A few different approaches:
- Clients try to connect to the node IP addresses randomly
- Round-robin DNS
- Using a TCP load balancer frontend (like F5, Coyote, HAProxy)
First solution requires the clients implement a strategy for connecting to the nodes and if a connection fails try another.
Round-robin DNS is similar to the first approach but the randomization is performed by DNS lookup rather than client directly.
Final solution is the most “correct” way to do it but requires additional hardware and a more complex setup.